Welcome to MrRobot5's Blog!
记录源码阅读心得、工作遇到的问题-
事务与消息发送同步方案
业务操作复杂后,发送 MQ 消息和数据库事务往往存在时序错位。事务尚未提交,消息已被消费者处理,导致数据查询失败。
本文的核心对象是 Spring 的
TransactionSynchronizationAdapter,通过注册事务提交回调,以最小代价实现”事务成功后才发送消息”的同步保障。关键结论:
TransactionSynchronization是单体应用内解决事务与外部交互一致性的轻量级方案,但若涉及主从延迟或网络延迟,则需要更复杂的分布式改造。问题场景
异常时序
当业务操作(如创建订单、异常单)和发送 MQ 任务消息在同一事务中执行时,如果在事务提交前就发送消息,消息消费者可能立即处理并查询数据库,此时事务还未提交,导致数据不一致。
/** * 问题代码示意:事务与消息发送时序错误 */ @Transactional public void createOrder(Order order) { orderMapper.insert(order); // 1. 数据库操作 mqProducer.send(orderMessage); // 2. 事务未提交,消息已发送 ❌ // 3. 其他耗时操作(业务逻辑、外部调用等)。消息消费者查询不到新增的数据 ❌ // 4. 事务提交在此之后 }🙉 消费者收到消息后查询数据库,可能查不到刚插入的数据——因为事务还未提交。
问题本质
核心矛盾在于事务边界与外部交互边界的错位:
阶段 消息发送时机 消费者查询结果 事务提交前发消息 消息已发送,但数据未提交 ❌ 查不到数据 事务提交后发消息 数据已提交,消息后发送 ✅ 正常查询 🎈 在单体应用、同库事务场景下,理想的方案是:让消息发送这个”外部交互”延迟到事务真正提交之后。
核心方案:TransactionSynchronizationAdapter
方案设计
Spring 提供了
TransactionSynchronization接口,允许将自定义逻辑注册到事务生命周期中。其中afterCommit()回调会在事务成功提交后触发,afterCompletion()则在事务完成(无论成功或失败)后触发。🎈 选择
afterCommit()而非afterCompletion()的原因是:只有事务成功提交后才需要发送消息;事务回滚时,数据未落库,不应发送消息。/** * 事务提交后才发送 MQ 消息 * @see org.springframework.transaction.support.TransactionSynchronizationAdapter */ public <T extends MQTaskMessageBaseDto> void sendMQTask(T messageBody) { if (TransactionSynchronizationManager.isSynchronizationActive()) { log.info("sendMQTask--事务提交后再发送消息:{}", messageBody); // 注册事务同步回调,延迟到事务提交后执行 TransactionSynchronizationManager.registerSynchronization( new TransactionSynchronizationAdapter() { @Override public void afterCommit() { doSendMQTask(messageBody); // 事务已提交,安全发送 } }); } else { log.info("sendMQTask--直接发送消息:{}", messageBody); doSendMQTask(messageBody); // 无事务上下文,直接发送 } }执行时序
sequenceDiagram participant 业务服务 participant 数据库 participant MQ消息队列 业务服务->>数据库: 1. 开启事务 业务服务->>数据库: 2. 执行数据库操作 业务服务->>业务服务: 3. registerSynchronization<br/>(afterCommit 回调) 业务服务->>业务服务: 4. 其他耗时操作<br/>(业务逻辑、外部调用等) 业务服务->>数据库: 5. 提交事务 数据库-->>业务服务: 6. 事务提交成功 业务服务->>MQ消息队列: 7. afterCommit() 触发<br/>发送 MQ 任务消息 Note over MQ消息队列: ✅ 消息发送时数据已提交✔ 这种方案的优势在于零侵入——业务代码不需要关心事务状态,统一封装在消息发送层。
优点与局限
⭐ 优点:复杂度低,Spring 原生支持; 实现难度低,代码量少
🎈 不足:如果涉及主从延迟(消息发送后消费者读从库,数据尚未同步)或网络延迟(消息先于事务提交传播到消费者),则需要更复杂的分布式改造方案(如本地消息表、事务消息等)。
扩展场景:缓存更新和事务一致性
TransactionSynchronizationAdapter的应用不仅限于 MQ 消息发送。Spring Cache 模块中,TransactionAwareCacheManagerProxy正是基于同样的思想,为缓存操作添加事务感知能力。背景:缓存与事务的脏数据问题
某些缓存管理器(如
SimpleCacheManager)不支持直接的事务感知。如果在事务中先更新缓存、后回滚事务,缓存中就会残留脏数据:@Transactional public void updateData(Data data) { cache.put(data.getId(), data); // 1. 缓存已更新 dataMapper.update(data); // 2. 数据库操作 // 3. 抛出异常,事务回滚 // 结果:缓存是新数据,数据库是旧数据 ❌ }TransactionAwareCacheManagerProxy 的设计
TransactionAwareCacheManagerProxy基于组合模式,为不支持事务感知的CacheManager添加事务同步能力。它本质上是TransactionAwareCacheDecorator装饰目标Cache实例,将缓存写操作与 Spring 管理的事务绑定。/** * 事务感知缓存装饰器 * @see org.springframework.cache.transaction.TransactionAwareCacheDecorator */ public class TransactionAwareCacheDecorator implements Cache { private final Cache targetCache; @Override public void put(final Object key, final Object value) { if (TransactionSynchronizationManager.isSynchronizationActive()) { // 存在活动事务时,延迟缓存写操作到事务提交后 TransactionSynchronizationManager.registerSynchronization( new TransactionSynchronizationAdapter() { @Override public void afterCommit() { targetCache.put(key, value); // 事务提交后真正写入缓存 } }); } else { targetCache.put(key, value); // 无事务,直接写入 } } // evict、clear 等操作同理延迟执行 }🎈 核心逻辑与 MQ 发送方案完全一致:存在活动事务时,
put、evict、clear等操作被注册到TransactionSynchronizationManager,延迟到事务成功提交后才真正执行。若事务回滚,这些缓存操作自然失效,不会污染缓存。✔ 这种装饰器模式的设计非常优雅:不修改原有缓存管理器的实现,仅通过代理层增强事务感知能力,符合开闭原则。
其他同步方案
在分布式场景或更高可靠性要求下,还有以下方案可供选择:
方案 复杂度 可靠性 实现难度 适用场景 本地消息表 ⭐⭐⭐ 高 中 跨服务 / 跨库场景,需持久化消息 RocketMQ 事务消息 ⭐⭐⭐ 高 中 已使用 RocketMQ,两阶段提交 定时扫描补偿 ⭐⭐ 中 低 简单场景,允许最终一致性延迟 Seata 分布式事务 ⭐⭐⭐⭐ 高 高 强一致性要求,改造代价大 🎈 选型建议:单体应用优先使用
TransactionSynchronization(本文方案);跨服务、跨库场景考虑本地消息表或 RocketMQ 事务消息;对一致性要求极高且可接受高改造成本时,再考虑分布式事务框架。总结
TransactionSynchronizationAdapter是 Spring 原生的事务生命周期钩子,以最小代码量实现”事务提交后执行外部操作”的同步保障。- 核心模式是延迟执行:将非事务性操作(MQ 发送、缓存更新)注册为
afterCommit回调,绑定到事务成功提交后才真正执行。 TransactionAwareCacheManagerProxy是同一思想的经典应用,通过装饰器模式为缓存添加事务感知,避免事务回滚后的脏数据问题。- 该方案适用于单体应用 / 同库事务场景,实现简单、无额外依赖;若存在主从延迟、网络延迟或跨服务分布式场景,则需升级为本地消息表、事务消息等更复杂的方案。
- 技术选型的原则:在满足可靠性要求的前提下,优先选择复杂度最低的方案。⭐
-
node-sass 兼容问题与 webpack loader 的巧妙设计
在维护一个老前端工程时,本地
npm run dev突然无法启动。追根溯源,发现是 node-sass@6.0.1 在 Apple Silicon (M1/M2) 架构上报错。替换为 dart-sass 后,又因为代码中使用了已被废弃的/deep/深度选择器语法而编译失败。目标很明确:❌ 不修改已有工程的源码和配置,通过 webpack loader 的巧妙编排,实现本地服务的无痛启动。
最终方案是:在
sass-loader之后注入string-replace-loader,将/deep/替换为::v-deep,并借此机会深入理解 webpack loader 的设计哲学。异常场景
工程配置
该工程是一个基于 Vue 2.x 的老项目,构建工具使用 webpack 4,样式处理器配置如下:
// webpack.config.js 片段 { test: /\.scss$/, use: [ 'vue-style-loader', 'css-loader', 'sass-loader' // 内部依赖 node-sass ] }// package.json 片段 { "dependencies": { "node-sass": "^6.0.1" } }异常表现
在新的 MacBook Pro (M1 Pro, arm64) 上执行
npm install时,node-sass安装阶段直接报错:Error: Node Sass does not yet support your current environment: OS X Unsupported architecture (arm64)🙉 错误信息非常直接:当前操作系统架构为 arm64,而 node-sass@6.0.1 的预编译二进制包仅支持 x64。这是一个架构级别的硬兼容性问题,无法通过简单的降级或升级 Node.js 版本解决。
场景复现
① node-sass 安装失败
node-sass 是一个 Node.js 到 libsass 的绑定库,libsass 使用 C++ 编写。发布时,node-sass 会针对特定平台(OS + 架构 + Node 版本)提供预编译的
.node二进制文件。Downloading binary from https://github.com/sass/node-sass/releases/download/v6.0.1/ darwin-arm64-83_binding.node Cannot download "https://github.com/sass/node-sass/releases/download/v6.0.1/darwin-arm64-83_binding.node"❌ 查看 node-sass release 页面,v6.0.1 的 release assets 中仅有
darwin-x64包,没有darwin-arm64。② dart-sass 编译报错
既然 node-sass 不支持 arm64,自然的替代方案是使用 dart-sass(即
sass包)。dart-sass 是 Sass 的官方实现,纯 JavaScript/ Dart 编译,没有原生依赖,跨平台支持极好。npm uninstall node-sass npm install sass --save-dev然而项目启动后,编译阶段报错:
SassError: expected selector. /deep/ .some-class ^❌ 原因是:工程源码中大量使用了 Vue 的
/deep/深度选择器语法,而 dart-sass 2.0+ 已完全废弃/deep/,仅支持::v-deep。这导致大量的.scss文件无法通过编译。问题分析
node-sass 的架构绑定
node-sass 的核心问题在于其强平台绑定的设计。它依赖 libsass(C++ 库),必须通过 node-gyp 编译或在发布时提供预编译二进制文件。这种架构在平台迁移期(如 x86_64 → arm64)会暴露严重的兼容性缺陷:
node-sass → libsass (C++) → 平台特定二进制 → 强绑定 OS + CPU 架构 + Node ABI 版本🎈 相比之下,dart-sass 是 Sass 官方推荐的实现,使用 Dart 编译为 JavaScript(或原生可执行文件),完全脱离平台二进制依赖,是未来趋势。node-sass 本身也已于 2020 年被官方标记为废弃(deprecated)。
/deep/ 的废弃历程
/deep/原本是 CSS Shadow DOM 规范中的>>>选择器的别名,Vue 在 scoped CSS 中借用它来实现样式穿透。但 CSS 工作组已废弃/deep/,Sass 编译器随之跟进:版本 行为 libsass (node-sass) 仍支持 /deep/作为普通选择器dart-sass < 1.23 支持,但发出 deprecation warning dart-sass ≥ 2.0 ❌ 完全废弃,编译报错 🎈 问题的矛盾点在于:源码是旧的,但构建工具必须升级。修改所有源码中的
/deep/为::v-deep虽然可行,但会引入大量无意义的 diff,且可能触发其他老浏览器兼容问题。最好的方案是在编译阶段做”兼容转换”。解决方案
① 替换为 dart-sass
首先,卸载 node-sass,安装 dart-sass:
npm uninstall node-sass npm install sass --save-dev✔ 此时
sass-loader会自动探测并使用sass包(dart-sass),无需修改webpack.config.js中的 loader 名称。② string-replace-loader 配置
接下来,引入
string-replace-loader,在 sass 编译之前(从源码角度看,是 loader 链的右侧)将/deep/替换为::v-deep:npm install string-replace-loader --save-dev// webpack.config.js 修改后 { test: /\.scss$/, use: [ 'vue-style-loader', 'css-loader', { loader: 'sass-loader', options: { // 可根据需要配置 additionalData 等 } }, { loader: 'string-replace-loader', options: { search: '/deep/', replace: '::v-deep', flags: 'g' // 全局替换 } } ] }🎈 关键点:webpack loader 的执行顺序是从右到左,从下到上。数组右侧的 loader 先执行,处理最原始的源码;处理后的结果向左传递。因此将
string-replace-loader放在sass-loader的右侧(即数组中的下方/后面),它会在 sass 编译之前先执行文本替换。另一种等价的配置方式(使用
enforce: 'post'或 webpack chain 的after):// vue.config.js 中使用 webpack-chain config.module .rule('scss') .use('string-replace-loader') .loader('string-replace-loader') .after('sass-loader') // 确保在 sass-loader 之后执行(数组右侧) .options({ search: '/deep/', replace: '::v-deep', flags: 'g' });after('sass-loader')会将string-replace-loader插入到sass-loader的后面(数组的右侧),符合从右到左的执行顺序。③ loader 顺序验证
为了验证 loader 的调用顺序,可以通过以下方式确认:
// 自定义一个 debug loader 验证执行顺序 const debugLoader = { loader: 'string-replace-loader', options: { search: '/deep/', replace: '::v-deep', flags: 'g' } }; // 执行顺序:string-replace-loader → sass-loader → css-loader → vue-style-loader // 即:先替换文本,再编译 sass,再处理 css,最后注入样式✔ 验证通过后,工程可以正常启动,所有
/deep/语法在编译阶段被静默替换,源码无需任何改动。扩展:webpack loader 的设计思想
本次问题能够优雅解决,核心得益于 webpack loader 的精妙设计。下面从三个维度展开分析。
① 链式调用与从右到左执行
webpack loader 的配置是一个数组,但执行顺序并非直觉上的从左到右,而是从右到左,从后往前:
use: [A, B, C] 执行顺序:C → B → A🎈 这种设计暗合了函数组合(Function Composition)的数学直觉。如果每个 loader 是一个函数
f(resource),那么整个 loader 链等价于:const result = A(B(C(source)));即最右侧的 loader 先接触原始资源,经过层层转换后,最左侧的 loader 输出最终结果给 webpack 的模块系统。这种设计使得:
- 源码预处理(如替换、转译)放在右侧,先执行;
- 后处理(如样式注入、资源打包)放在左侧,最后执行。
本案例中的 loader 执行顺序如下:
graph LR A[原始源码] --> B[string-replace-loader] B --> C[sass-loader] C --> D[css-loader] D --> E[vue-style-loader] E --> F[最终输出] style B fill:#e1f5fe,stroke:#01579b style C fill:#e1f5fe,stroke:#01579b style D fill:#e1f5fe,stroke:#01579b style E fill:#e1f5fe,stroke:#01579b② 单一职责与管道模式
每个 loader 只负责一种转换,这是单一职责原则(SRP)的典型实践:
Loader 职责 string-replace-loader纯文本替换,不解析 AST sass-loader将 Sass/SCSS 编译为 CSS css-loader解析 CSS 中的 @import和url(),处理模块化vue-style-loader将 CSS 注入 DOM 的 <style>标签🎈 这种管道模式(Pipeline Pattern)的好处是:loader 之间完全解耦。
string-replace-loader不需要知道 Sass 语法,只需要按字符串规则替换;sass-loader也不需要关心源码中是否包含/deep/,它只负责编译标准的 SCSS。每个组件专注做好一件事,通过标准接口(字符串输入 → 字符串输出)串联起来。③ loader 的本质:内容转换函数
从源码层面看,一个 loader 本质上是一个符合特定签名的 JavaScript 函数:
/** * webpack loader 的标准接口 * @see webpack/lib/NormalModuleLoaderContext.js * @param {string|Buffer} source 模块源码内容 * @returns {string|Buffer} 转换后的内容 */ module.exports = function(source) { // 对 source 进行任意转换 const result = source.replace(//deep\//g, '::v-deep'); return result; };🎈 这意味着 loader 拥有极大的灵活性:
- 它可以是无状态的纯函数(如
string-replace-loader); - 也可以是有状态的(通过
this上下文访问 webpack 的 loader API); - 甚至可以是异步的(通过
this.async()回调)。
webpack 只关心输入输出契约,不关心内部实现,这正是 loader 生态能够蓬勃发展的根本原因。
总结
- node-sass 的 arm64 兼容问题是原生绑定库的共性问题,dart-sass 作为纯 JS 实现是更现代的替代方案。
- 不修改源码的前提下,通过
string-replace-loader在编译阶段做语法兼容,是一种低侵入、可回滚的优雅方案。 - webpack loader 从右到左的执行顺序是函数组合思想的工程体现,理解这一点是正确配置 loader 链的关键。
- 单一职责 + 管道模式使得 loader 生态高度解耦、可扩展,每个 loader 只需关注一种转换,通过编排解决复杂问题。
- 老工程的维护艺术往往不在于重写,而在于找到基础设施层面的兼容层,让旧代码在新环境中继续稳定运行。⭐
-
类加载机制引起 Spring 属性解析异常分析
在使用 Idea 开发Spring 应用过程中,突然有一次应用启动报错:Could not resolve placeholder ‘mq.address’ in value “${mq.address}”
由此开始此次的源码阅读和异常分析。
最后追踪分析是 JRebel 类加载器的作用机制 导致的异常。
异常场景
工程配置
Spring Boot 配置
@ImportResource({ "classpath:spring/spring-mq-producer.xml", "classpath:spring/spring-bean.xml", }) @PropertySource(value = "classpath:important.properties", encoding = "utf-8") @Slf4j public class WebApplication extends SpringBootServletInitializer { }spring-bean.xml 文件配置
<!-- 以通配符的形式引入属性文件 --> <context:property-placeholder location="classpath:*.properties"/>异常表现
通过 @PropertySource 配置的属性可以解析并替换占位符✔
通过 context:property-placeholder 配置的属性解析不到,直接报错❌
场景复现
// demo: resolver 查找类路径文件的过程。 // 问题复现:需要在当前工程中引入异常的jrebel.xml, 使用JRebel 启动。⭐ public static void main(String[] args) { PathMatchingResourcePatternResolver resolver = new PathMatchingResourcePatternResolver(); try { // 查找类路径下的所有 *.properties 文件 Resource[] resources = resolver.getResources("classpath:*.properties"); printResources("classpath:*.properties", resources); } catch (IOException e) { e.printStackTrace(); } }问题分析
根据相关源码,初步定位在
PropertySourcesPlaceholderConfigurersetLocations 初始化时,注入的文件是空的,导致无法成功引入属性文件。进一步 debug 定位分析,发现 ClassLoader#getResource 过程中,classpath 路径不是当前工程的。
👉通过分析 classpath 相关jar, 发现依赖的 jar 包含 rebel.xml 文件。JRebel会根据
rebel.xml配置文件中的 classpath 配置扫描指定的目录和 JAR 文件。这样,查找文件不是当前工程目录(/workspace/another.foo.com/target/classes),肯定找不到配置文件。
JRebel 类加载器与 Spring 属性解析的冲突流程如下:
graph TD A[Spring 启动] --> B[解析 context:property-placeholder] B --> C[PathMatchingResourcePatternResolver<br/>查找 classpath:*.properties] C --> D{ClassLoader 类型} D -->|正常 AppClassLoader| E[扫描当前工程 target/classes] D -->|JRebel 类加载器| F[扫描 rebel.xml 配置的目录] F --> G[路径指向 /workspace/another.foo.com<br/>❌ 非当前工程] G --> H[找不到 *.properties 文件] H --> I[PropertySourcesPlaceholderConfigurer<br/>locations 为空] I --> J[占位符解析失败<br/>Could not resolve placeholder] E --> K[正常加载属性文件] style D fill:#e1f5fe,stroke:#01579b style F fill:#fff3e0,stroke:#e65100 style G fill:#ffebee,stroke:#c62828 style J fill:#ffebee,stroke:#c62828 style K fill:#e8f5e9,stroke:#2e7d32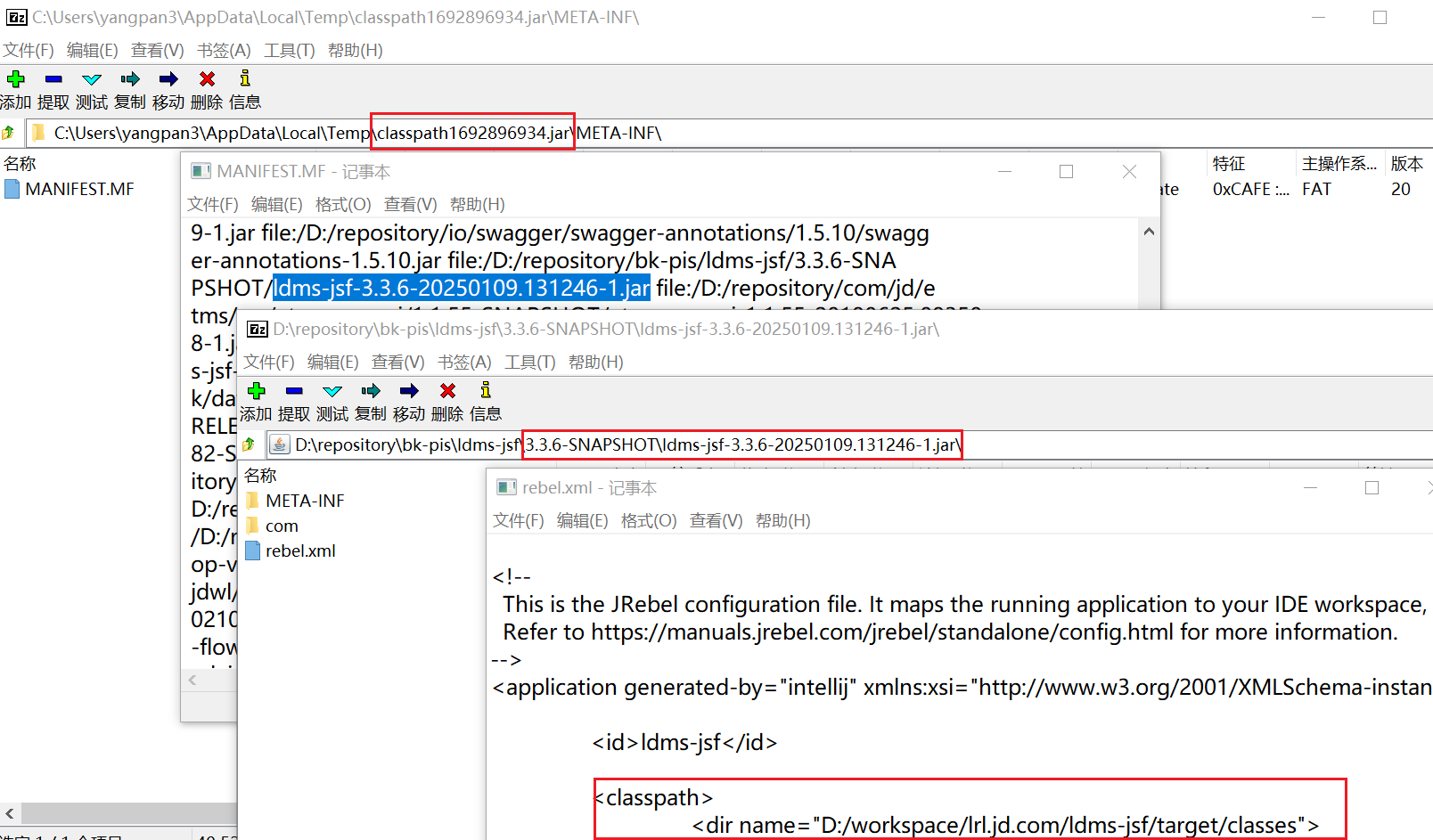
-
数据层中间件使用二三事
近期在运维和改造旧系统的过程中,遇到了几个Mybatis 缓存、Spring 事务管理、数据库连接池影响事务隔离级别的问题。
特此记录问题的场景和主要原因,方便后续避坑和查阅。
Mybatis 一级缓存
①问题场景
使用 Mybatis 从数据库中查询的数据,再次查询发现前后两次查询结果不一致。
问题场景的代码示例:
BlogMapper bMapper = session.getMapper(BlogMapper.class); Blog blog = bMapper.selectBlog(2); System.out.println(blog.getName()); blog.setName("changed"); // 再次查询相同的数据时,MyBatis 会直接从缓存中获取结果,而不再执行 SQL 语句。 Blog blog2 = bMapper.selectBlog(2); // 打印结果:"changed"。 blog 和 blog2 为同一对象。🎈 System.out.println(blog2.getName());②分析过程
由于业务逻辑比较复杂,第一次查询的结果,在其他方法中对属性重新赋值。导致的现象比较奇怪。
通过开启 debug日志,打印 Mybatis SQL, 第二次查询没有发起 SQL 请求(再次执行相同的 SQL 语句时,MyBatis 会直接从缓存中获取结果,而不再发送 SQL 请求到数据库)。
Mybatis 使用了一级缓存。两次查询结果是同一对象。
/** * 一级缓存是 MyBatis 默认开启的缓存机制,它是基于 SqlSession 级别的缓存。 * @see BaseExecutor#query(MappedStatement, Object, RowBounds, ResultHandler, CacheKey, BoundSql) */ public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { // By default, flushCacheRequired is false for select statements if (queryStack == 0 && ms.isFlushCacheRequired()) { clearLocalCache(); } try { // 相同 SQL (CacheKey 一样)再次查询,直接从缓存中获取结果。 list = resultHandler == null ? (List<E>) localCache.getObject(key) : null; if (list != null) { handleLocallyCachedOutputParameters(ms, key, parameter, boundSql); } else { // 发送 SQL 请求到数据库 list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql); } } return list; }③相关知识
-
MyBatis 一级缓存(Local Cache)是 MyBatis 默认开启的缓存机制,它是基于 SqlSession 级别的缓存。
-
缓存失效场景:执行 SqlSession 的增删改操作(如 insert, update, delete),会清空一级缓存。
Spring 事务嵌套
①问题场景
为了解决大事务更新过程中,多事务间数据不可见的问题。
在后置处理方法中开启新事务,调整事务隔离级别为 READ_UNCOMMITTED。方便汇总计算逻辑可以及时共享数据。
带来的问题是: 有一定概率抛出异常 CannotAcquireLockException
Error updating database. Cause: java.sql.SQLException: Lock wait timeout exceeded; try restarting transaction
②分析过程
开启新事务,用的是 Spring事务管理
REQUIRES_NEW传播行为。将当前事务 A 挂起,创建一个新的事务 B。
事务 A 中发起某条数据的update, 尚未提交。事务 B 同样发起这条数据的 update, 导致超时锁等待异常。
参考数据库的锁机制: Insight h2database 更新、读写锁以及事务原理
③总结
-
这个问题是个典型的资源竞争 (Resource Contention)/死锁 (Deadlock) 问题。
-
使用Spring 事务嵌套,需要特别注意更新数据的边界。尽量有充分的测试和验证,避免线上事故。
DBCP 事务隔离级别失效
①问题场景
在Spring 事务管理中,通过配置
Isolation.READ_UNCOMMITTED,修改当前会话/数据库连接的事务隔离级别。在测试验证中,其他事务更新过程中的数据,当前事务中 select 结果中没有。
也就是说,事务隔离级别并没有生效。
②分析过程
排查思路:使用 JdbcTemplate 以及原生 Jdbc API 开启事务隔离级别,把问题范围缩小并定位到数据库连接池组件(DBCP)上。
/** * 验证数据库连接的有效性 * @param sql 如果sql参数是null或为空字符串,代码会调用连接的isValid(timeout)方法来检查连接是否有效。 * 如果sql参数不为null,代码会执行这条SQL作为一个查询,并检查结果集(ResultSet)是否至少包含一行。 * @see org.apache.commons.dbcp2.PoolableConnectionFactory#validateConnection * @see org.apache.commons.dbcp2.PoolableConnection#validate */ public void validate(final String sql, int timeout) throws SQLException { if (sql == null || sql.length() == 0) { // java.sql.Connection.isValid if (!isValid(timeout)) { throw new SQLException("isValid() returned false"); } return; } if (!sql.equals(lastValidationSql)) { lastValidationSql = sql; // 此处创建了prepareStatement, 并缓存到当前 connection ❌ validationPreparedStatement = getInnermostDelegateInternal().prepareStatement(sql); } }👉DBCP validationQuery 事务隔离级别失效 Example. TransactionIsolationExample
Spring 事务开启前、数据库连接池获取 Connection 之前,由于DBCP 已经创建了 prepareStatement, 导致后续再次设置事务隔离级别失效。
-
-
JQuery-data-设计分析
JQuery 的data 功能可以动态的存取数据,不用频繁的操作DOM。
在事件处理程序之间传递数据非常有用。
JQuery Data
JQuery 定义一个
Data构造函数。默认实例化两个Data对象(dataUser、dataPriv)供功能使用。🎈数据的存取实现,就是通过 Data 来定义和实现。
①get 方法
function Data() { // 每次实例化 Data 对象时,都会生成一个唯一的 expando 属性值。 this.expando = jQuery.expando + Data.uid++; } // 通过设置原型对象,定义 Data 实例共享的方法和属性。 Data.prototype = { /** * 数据获取 * @param {*} owner 对应到 data功能,就是 Dom 对象 * @param {*} key 可以为空, 如果不指定,获取 owner 绑定的所有数据。 * @returns */ get: function( owner, key ) { return key === undefined ? // 类似于 owner[ this.expando ] this.cache( owner ) : // 如果存在 expando 属性值,则返回 owner[ this.expando ][ camelCaseKey ] 的值 owner[ this.expando ] && owner[ this.expando ][ jQuery.camelCase( key ) ]; } }② data 方法
抽象定义和初始化 Data 对象后,使用dataUser 操作Dom 存取数据变的很方便。
同时兼容了HTML5 data-* 特性,读取数据后类型转换并同步到 dataUser 中。
/** * 扩展 jQuery 实例方法,扩展后的方法可以在所有 jQuery 对象实例上调用。例如:$('p').data('someData'); * 对比:jQuery.extend。用于扩展 jQuery 构造函数的静态方法或属性。$.data(elem, 'someData') */ jQuery.fn.extend( { /** * 从dom 对象存取数据。value 有值是set 操作,无值是get 操作 * @param {*} key 数据key * @param {*} value 允许为空 * @returns */ data: function( key, value ) { var elem = this[ 0 ]; return access( this, function( value ) { var data; // get 操作 if ( elem && value === undefined ) { data = dataUser.get( elem, key ); if ( data !== undefined ) { return data; } // 兼容 HTML5 custom data-* attrs // 如果获取到 data-* 字符串,会尝试进行类型转换,或者json 反序列化 data = dataAttr( elem, key ); if ( data !== undefined ) { return data; } // We tried really hard, but the data doesn't exist. return; } // set 操作 this.each( function() { dataUser.set( this, key, value ); } ); }, null, value, arguments.length > 1, null, true ); } })③ 字符串类型转换
类型转换方便了取值后的操作,同时 JavaScript 类型的隐含转换也需要注意。🎈
// 用于匹配一个完整的 JSON 对象或数组。 // 1. 以 `{` 开头,以 `}` 结尾,中间可以包含任意字符。 // 2. 以 `[` 开头,以 `]` 结尾,中间可以包含任意字符。 var rbrace = /^(?:\{[\w\W]*\}|\[[\w\W]*\])$/; /** * 尝试对字符串类型转换 * @param {*} data HTML5 data-* attribute * @returns */ function getData(data) { if (data === "true") { return true; } if (data === "false") { return false; } if (data === "null") { return null; } // 检查 data 是否是一个数字的字符串的技巧 // 如果是数字,则返回true。 如果非数字, +data 结果为 NaN。 if (data === +data + "") { // 需要特别注意,+data 将空字符串 "" 转换为数字 0。 return +data; } if (rbrace.test(data)) { return JSON.parse(data); } return data; }JQuery expando 设计
JQuery.expando是 jQuery 用来在 DOM 元素或其他对象上存储数据的一个独特属性。简化示例
var elem = document.getElementById("example"); // jQuery 内部会做类似的操作 elem["jQuery123456789"] = { "myData": "someValue" }; // 获取数据 var data = elem["jQuery123456789"]["myData"]; console.log(data); // 输出 "someValue"设计分析
数据隔离/避免冲突
JQuery.expando是一个唯一的字符串(通常是由 jQuery 生成的一个带有前缀和随机数的字符串),确保它在所有元素和对象上都是唯一的。这可以避免与其他属性或数据键发生冲突。// Unique for each copy of jQuery on the page expando: "jQuery" + ( version + Math.random() ).replace( /\D/g, "" ),性能优化
直接在元素或对象上存储数据(而不是使用全局数据存储)可以提高性能。访问和修改元素上的属性通常比通过全局数据存储更快,因为它减少了查找和管理的开销。