Welcome to MrRobot5's Blog!
记录源码阅读心得、工作遇到的问题-
Spring BeanCopier Bug
使用Spring BeanCopier 拷贝对象过程中,发现了一个Bug。
问题版本:3.2.0.RELEASE
Bug 场景
BeanCopier是一个非常高效的复制工具,因为它在运行时生成字节码来执行复制操作,而不是使用反射。①需要拷贝的类🧲
public static class TargetBean { private String name; // name's getters and setters // 没有 mixed 属性,Introspector 识别为布尔类型的 getter 方法 public String isMixed() { return name.contains("mix"); } }②拷贝异常❌
// 创建 BeanCopier 实例。 // 作用原理:使用CGlib库生成一个新类,该类的目的是实现Java Bean 之间属性的复制。 // 在匹配和获取 TargetBean setters过程中,出现异常 java.lang.NullPointerException BeanCopier copier = BeanCopier.create(TargetBean.class, TargetBean.class, false); // 复制属性 copier.copy(source, target, null);③日常日志
Exception in thread "main" java.lang.NullPointerException at org.springframework.cglib.core.ReflectUtils.getMethodInfo(ReflectUtils.java:424) at org.springframework.cglib.beans.BeanCopier$Generator.generateClass(BeanCopier.java:133) at org.springframework.cglib.core.DefaultGeneratorStrategy.generate(DefaultGeneratorStrategy.java:25) at org.springframework.cglib.core.AbstractClassGenerator.create(AbstractClassGenerator.java:216) at org.springframework.cglib.beans.BeanCopier$Generator.create(BeanCopier.java:90) at org.springframework.cglib.beans.BeanCopier.create(BeanCopier.java:50)问题分析
创建BeanCopier 实例的过程中,会根据TargetBean 遍历所有的 setter方法,尝试找到与之对应的 getter方法。
如上述的场景,针对属性“mixed”, 并没有对应的 setter方法,所以报错。
为什么 BeanCopier 会出现没有判断 null 的低级错误呢?🙉
①Introspector
Java Bean 是一种特殊的 Java 类,遵循特定的命名规则,比如属性的命名方式、事件处理方法等。
Introspector类使得开发者能够通过反射机制来分析一个 Java Bean 的属性和方法,而不需要直接与类的代码交互。// Introspector 识别的命名约定🧲 // 属性的读取方法(getter) static final String GET_PREFIX = "get"; // 属性的设置方法(setter) static final String SET_PREFIX = "set"; // 布尔属性的特殊读取方法。对于返回类型为 boolean 的属性,按照习惯,其读取方法可以使用 "is" 前缀而不是 "get"。 static final String IS_PREFIX = "is";根据约定,TargetBean 中的 isMixed 方法会识别为“mixed”属性的读取方法。
②BeanCopier
/** * 用CGlib库生成一个新类的过程,实现两个Java Bean之间属性的复制。 * @see org.springframework.cglib.beans.BeanCopier.Generator#generateClass */ public void generateClass(ClassVisitor v) { Type sourceType = Type.getType(this.source); Type targetType = Type.getType(this.target); PropertyDescriptor[] getters = ReflectUtils.getBeanGetters(this.source); // Bug: mixed 属性描述符也会返回到 setters集合中。实际上,该属性描述符并没有 WriteMethod。 // fix: setters = ReflectUtils.getBeanSetters(this.target); PropertyDescriptor[] setters = ReflectUtils.getBeanGetters(this.target); // 遍历所有的setter方法,尝试找到与之对应的getter方法。 for(int i = 0; i < setters.length; ++i) { PropertyDescriptor setter = setters[i]; PropertyDescriptor getter = (PropertyDescriptor)names.get(setter.getName()); if (getter != null) { MethodInfo read = ReflectUtils.getMethodInfo(getter.getReadMethod()); // mixed 属性的描述符(setter)对应的 WriteMethod = null, 所以抛异常。 MethodInfo write = ReflectUtils.getMethodInfo(setter.getWriteMethod()); if (compatible(getter, setter)) { e.dup2(); e.invoke(read); e.invoke(write); } } } }③导出动态类
可以自定义 ClassFileTransformer, 拦截类的加载过程,并在类被加载到 JVM 之前导出类的字节码。
👉生成的动态类路径和 copy 接口实现
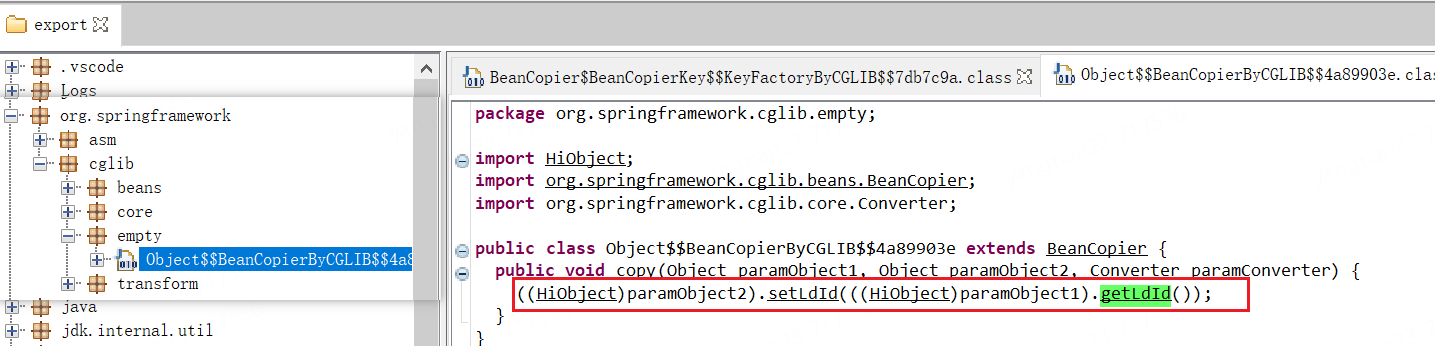
More
其实这个是CGLIB 的bug,从 Spring 3.2 开始,
CGLIB的功能被整合进了 Spring。这个Bug 在Spring 后续版本中已经被修复。✔
不过 cglib-nodep 修复比较慢, 使用cglib-nodep 需要注意这个问题。🎈
-
JDBC queryTimeout 实现机制
超时机制是个常见的设计,对于系统的稳定性和可靠性有重要的作用。
本文分别从 H2 和 Mysql 两种数据库的实现方式,来了解数据库查询的超时设计。
-
JDK-HttpURLConnection-超时管理机制
👉使用 JDK 的api 发起http 请求示例。http 请求连接超时其实是 Socket 连接超时。
URL url = new URL("https://raw.github.com/square/okhttp/master/README.md"); // 真正的网络请求通过 sun.net.www.protocol.https.HttpsClient 实现 // 底层通过Socket 来建立网络连接 HttpURLConnection connection = (HttpURLConnection) url.openConnection(); // 作为方法参数,透传调用 java.net.Socket#connect(endpoint, timeout) connection.setConnectTimeout(100);openConnection 并不会发起网络连接。只有主动调用 connect(),或者获取response 相关的操作,才会发起网络通信。socket 连接建立通过DualStackPlainSocketImpl 实现。
参考:sun.net.www.protocol.http.HttpURLConnection#connect
①DualStackPlainSocketImpl
DualStackPlainSocketImpl是 Java 中用于实现双栈 (IPv4/IPv6) 套接字的一个内部类。/** * 超时网络连接实现 * 如果设置超时时间,首先设置操作系统socket 非阻塞模式,然后等待timeout获取socket 状态。决定是否抛中断异常 * @param timeout 来自于 setConnectTimeout🎈 * @see DualStackPlainSocketImpl#socketConnect(InetAddress, int, int) */ void socketConnect(InetAddress address, int port, int timeout) throws IOException { if (timeout <= 0) { connectResult = connect0(nativefd, address, port); } else { // 设置I/O为非阻塞模式,对应JNI Java_java_net_DualStackPlainSocketImpl_configureBlocking configureBlocking(nativefd, false); try { // 非阻塞模式,直接返回 connectResult = connect0(nativefd, address, port); if (connectResult == WOULDBLOCK) { // 借助操作系统select api,实现超时等待。如果没有连接成功,则抛出异常 // 对应JNI Java_java_net_DualStackPlainSocketImpl_waitForConnect waitForConnect(nativefd, timeout); } } } }
-
AmazonHttpClient request 超时管理实现
通过使用计时器任务和中断机制,实现了对客户端执行HTTP请求超时的管理。
如果请求执行时间超过了设定的超时时间,则自动中断请求。
有效地避免因为网络问题或服务器响应慢导致的客户端线程长时间挂起的问题。
计时器中断方案
常用的资源管理方案,启动线程异步监控和中断工作任务。🎈
①整体方案实现
/** * 使用计时器方案,当http 请求超时,中断操作。 * @see com.amazonaws.http.timers.client.ClientExecutionTimer 中断计时器 * @see 源码 */ private Response<Output> executeWithTimer() throws InterruptedException { // 启动一个计时器(异步线程),这个计时器在客户端执行超时时会被触发。 ClientExecutionAbortTrackerTask clientExecutionTrackerTask = clientExecutionTimer.startTimer(getClientExecutionTimeout(requestConfig)); try { executionContext.setClientExecutionTrackerTask(clientExecutionTrackerTask); // 执行正常的 http 请求 return doExecute(); } finally { // 取消计时器任务,避免不必要的中断。 executionContext.getClientExecutionTrackerTask().cancelTask(); } }②中断任务调度
/** * 启动一个计时器任务(定时调度),当客户端执行超过指定的超时时间时,这个任务会被执行。 * @see com.amazonaws.http.timers.client.ClientExecutionTimer#scheduleTimerTask 源码 */ private ClientExecutionAbortTrackerTask scheduleTimerTask(int clientExecutionTimeoutMillis) { // 执行中断当前线程并中止HTTP请求。 ClientExecutionAbortTask timerTask = new ClientExecutionAbortTaskImpl(Thread.currentThread()); // 调度延迟任务 ScheduledFuture<?> timerTaskFuture = executor.schedule(timerTask, clientExecutionTimeoutMillis, TimeUnit.MILLISECONDS); return new ClientExecutionAbortTrackerTaskImpl(timerTask, timerTaskFuture); }③中断任务执行
/** * @see com.amazonaws.http.timers.client.ClientExecutionAbortTaskImpl 源码 */ public class ClientExecutionAbortTaskImpl implements ClientExecutionAbortTask { // 存储当前正在执行的HTTP请求 和任务线程,以便在需要时可以被中止。 private HttpRequestBase currentHttpRequest; private final Thread thread; /** * 触发时中断调用线程并中止HTTP请求。 */ public void run() { if (!thread.isInterrupted()) { thread.interrupt(); } if (!currentHttpRequest.isAborted()) { // 调用httpclient abortConnection()。 // Closes this socket. currentHttpRequest.abort(); } } }
-
SpringBoot ErrorPage 案例以及 Servlet 配置原理
SpringBoot ErrorPage 案例
案例描述
调用后端接口,发现接口返回的数据有两组 json, 非数组。非常奇怪🙉
{ "name": "John", "age": 30 } { "path": "/examples/servlets/servlet/JsonExample", "code": 500 }SpringMVC 运行时异常
/** * Servlet 包版本问题,导致 SpringMVC Servlet 打印日志报错 * @see org.springframework.web.servlet.FrameworkServlet#processRequest */ protected final void processRequest(HttpServletRequest request, HttpServletResponse response) { try { doService(request, response); } catch (ServletException | IOException ex) { } finally { // HttpStatus httpStatus = HttpStatus.resolve(status); since 5.0 才有这个方法 ❌ logResult(request, response, failureCause, asyncManager); publishRequestHandledEvent(request, response, startTime, failureCause); } }问题分析
-
第一个 json 是业务逻辑返回内容。controller 逻辑没有发生异常,正常写入 response。
-
第二个 json 是 SpringMVC Servlet 发生异常后,由 Tomcat ErrorPage 转发到默认的错误处理 Servlet 生成的内容。
-
两个 json 内容通过 RequestDispatcher.include 方法,都写入到 response。
案例复现
借助 Tomcat examples 应用,可以快速搭建案例场景。✔
业务场景 Servlet
import javax.servlet.*; import javax.servlet.http.*; import java.io.IOException; import java.io.PrintWriter; // Servlet 中返回 JSON 字符串 public class JsonServlet extends HttpServlet { protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { response.setContentType("application/json"); response.setCharacterEncoding("UTF-8"); String json = "{\"name\": \"John\", \"age\": 30}"; PrintWriter out = response.getWriter(); out.print(json); // 业务内容写入 response, response 变为 submit 状态。 out.flush(); // 模拟上述 SpringMVC 异常 if(true) { throw new RuntimeException("Bad area ref "); } } }异常处理 Servlet
import javax.servlet.*; import javax.servlet.http.*; import java.io.IOException; import java.io.PrintWriter; // 对应 SpringBoot 提供的 BasicErrorController public class ErrorServlet extends HttpServlet { protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { String path = request.getRequestURI(); String json = "{\"path\": \"" + path + "\", \"code\": 500}"; PrintWriter out = response.getWriter(); out.print(json); } }errorPage 配置
<servlet> <servlet-name>JsonExample</servlet-name> <servlet-class>JsonServlet</servlet-class> </servlet> <servlet-mapping> <servlet-name>JsonExample</servlet-name> <url-pattern>/servlets/servlet/JsonExample</url-pattern> </servlet-mapping> <servlet> <servlet-name>ErrorExample</servlet-name> <servlet-class>ErrorServlet</servlet-class> </servlet> <!-- 对应的注册过程: org.springframework.boot.autoconfigure.web.BasicErrorController --> <servlet-mapping> <servlet-name>ErrorExample</servlet-name> <url-pattern>/error</url-pattern> </servlet-mapping> <!-- 对应: ErrorPageRegistry.addErrorPages(errorPage); --> <error-page> <exception-type>java.lang.RuntimeException</exception-type> <location>/error</location> </error-page>编译运行
cd /d/services/apache-tomcat-8.0.48/webapps/examples/WEB-INF/classes # /D/repository/javax/servlet/servlet-api/2.4/servlet-api-2.4.jar javac -cp servlet-api-2.4.jar JsonServlet.java javac -cp servlet-api-2.4.jar ErrorServlet.java运行 Tomcat。 访问链接 http://localhost:8080/examples/servlets/servlet/JsonExample
-