Welcome to MrRobot5's Blog!
记录源码阅读心得、工作遇到的问题-
类加载机制引起 Spring 属性解析异常分析
在使用 Idea 开发Spring 应用过程中,突然有一次应用启动报错:Could not resolve placeholder ‘mq.address’ in value “${mq.address}”
由此开始此次的源码阅读和异常分析。
最后追踪分析是 JRebel 类加载器的作用机制 导致的异常。
异常场景
工程配置
Spring Boot 配置
@ImportResource({ "classpath:spring/spring-mq-producer.xml", "classpath:spring/spring-bean.xml", }) @PropertySource(value = "classpath:important.properties", encoding = "utf-8") @Slf4j public class WebApplication extends SpringBootServletInitializer { }spring-bean.xml 文件配置
<!-- 以通配符的形式引入属性文件 --> <context:property-placeholder location="classpath:*.properties"/>异常表现
通过 @PropertySource 配置的属性可以解析并替换占位符✔
通过 context:property-placeholder 配置的属性解析不到,直接报错❌
场景复现
// demo: resolver 查找类路径文件的过程。 // 问题复现:需要在当前工程中引入异常的jrebel.xml, 使用JRebel 启动。⭐ public static void main(String[] args) { PathMatchingResourcePatternResolver resolver = new PathMatchingResourcePatternResolver(); try { // 查找类路径下的所有 *.properties 文件 Resource[] resources = resolver.getResources("classpath:*.properties"); printResources("classpath:*.properties", resources); } catch (IOException e) { e.printStackTrace(); } }问题分析
根据相关源码,初步定位在
PropertySourcesPlaceholderConfigurersetLocations 初始化时,注入的文件是空的,导致无法成功引入属性文件。进一步 debug 定位分析,发现 ClassLoader#getResource 过程中,classpath 路径不是当前工程的。
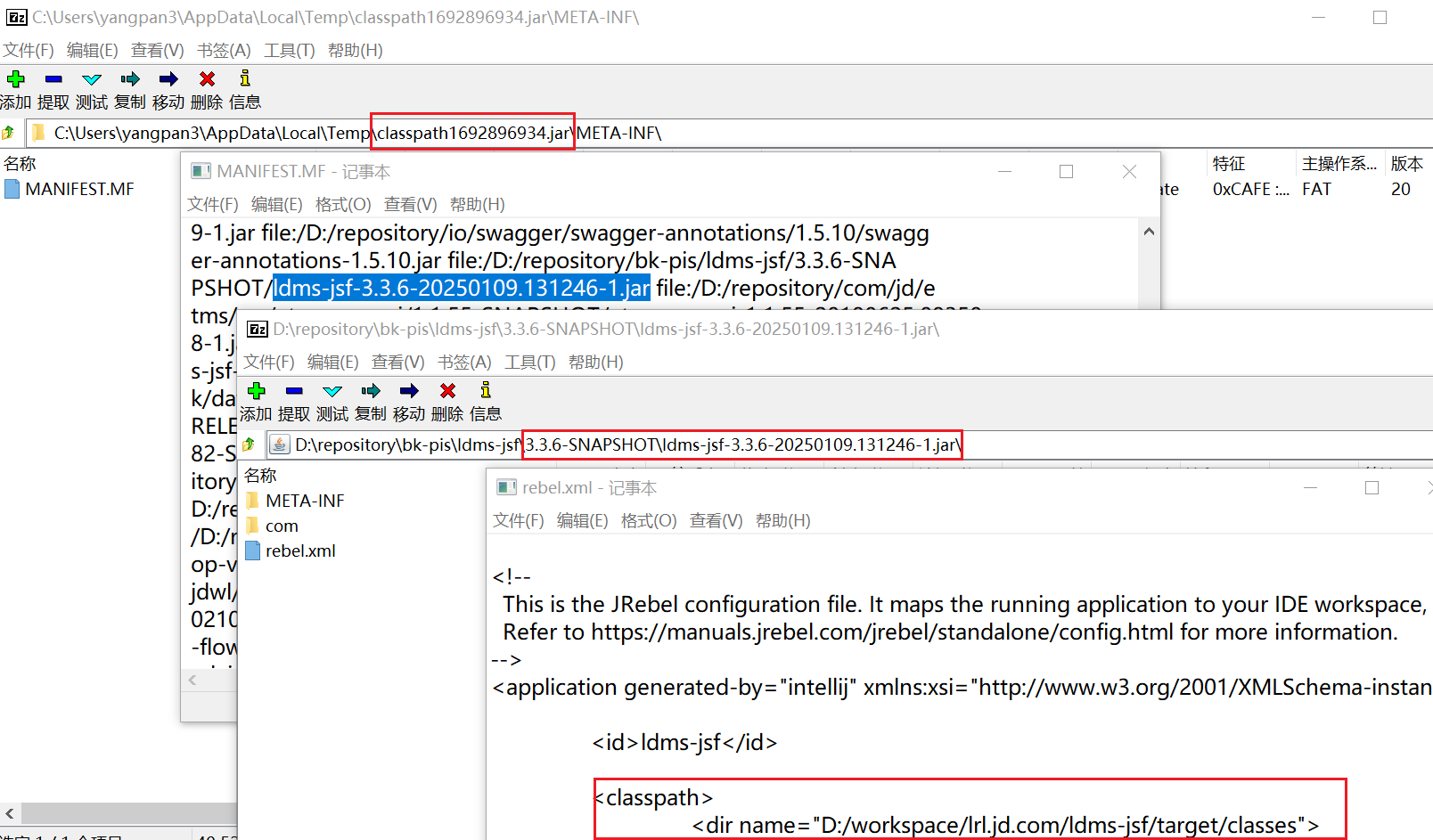
👉通过分析 classpath 相关jar, 发现依赖的 jar 包含 rebel.xml 文件。JRebel会根据
rebel.xml配置文件中的 classpath 配置扫描指定的目录和 JAR 文件。这样,查找文件不是当前工程目录(/workspace/another.foo.com/target/classes),肯定找不到配置文件。
-
数据层中间件使用二三事
近期在运维和改造旧系统的过程中,遇到了几个Mybatis 缓存、Spring 事务管理、数据库连接池影响事务隔离级别的问题。
特此记录问题的场景和主要原因,方便后续避坑和查阅。
Mybatis 一级缓存
①问题场景
使用 Mybatis 从数据库中查询的数据,再次查询发现前后两次查询结果不一致。
问题场景的代码示例:
BlogMapper bMapper = session.getMapper(BlogMapper.class); Blog blog = bMapper.selectBlog(2); System.out.println(blog.getName()); blog.setName("changed"); // 再次查询相同的数据时,MyBatis 会直接从缓存中获取结果,而不再执行 SQL 语句。 Blog blog2 = bMapper.selectBlog(2); // 打印结果:"changed"。 blog 和 blog2 为同一对象。🎈 System.out.println(blog2.getName());②分析过程
由于业务逻辑比较复杂,第一次查询的结果,在其他方法中对属性重新赋值。导致的现象比较奇怪。
通过开启 debug日志,打印 Mybatis SQL, 第二次查询没有发起 SQL 请求(再次执行相同的 SQL 语句时,MyBatis 会直接从缓存中获取结果,而不再发送 SQL 请求到数据库)。
Mybatis 使用了一级缓存。两次查询结果是同一对象。
/** * 一级缓存是 MyBatis 默认开启的缓存机制,它是基于 SqlSession 级别的缓存。 * @see BaseExecutor#query(MappedStatement, Object, RowBounds, ResultHandler, CacheKey, BoundSql) */ public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { // By default, flushCacheRequired is false for select statements if (queryStack == 0 && ms.isFlushCacheRequired()) { clearLocalCache(); } try { // 相同 SQL (CacheKey 一样)再次查询,直接从缓存中获取结果。 list = resultHandler == null ? (List<E>) localCache.getObject(key) : null; if (list != null) { handleLocallyCachedOutputParameters(ms, key, parameter, boundSql); } else { // 发送 SQL 请求到数据库 list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql); } } return list; }③相关知识
-
MyBatis 一级缓存(Local Cache)是 MyBatis 默认开启的缓存机制,它是基于 SqlSession 级别的缓存。
-
缓存失效场景:执行 SqlSession 的增删改操作(如 insert, update, delete),会清空一级缓存。
Spring 事务嵌套
①问题场景
为了解决大事务更新过程中,多事务间数据不可见的问题。
在后置处理方法中开启新事务,调整事务隔离级别为 READ_UNCOMMITTED。方便汇总计算逻辑可以及时共享数据。
带来的问题是: 有一定概率抛出异常 CannotAcquireLockException
Error updating database. Cause: java.sql.SQLException: Lock wait timeout exceeded; try restarting transaction
②分析过程
开启新事务,用的是 Spring事务管理
REQUIRES_NEW传播行为。将当前事务 A 挂起,创建一个新的事务 B。
事务 A 中发起某条数据的update, 尚未提交。事务 B 同样发起这条数据的 update, 导致超时锁等待异常。
参考数据库的锁机制: Insight h2database 更新、读写锁以及事务原理
③总结
-
这个问题是个典型的资源竞争 (Resource Contention)/死锁 (Deadlock) 问题。
-
使用Spring 事务嵌套,需要特别注意更新数据的边界。尽量有充分的测试和验证,避免线上事故。
DBCP 事务隔离级别失效
①问题场景
在Spring 事务管理中,通过配置
Isolation.READ_UNCOMMITTED,修改当前会话/数据库连接的事务隔离级别。在测试验证中,其他事务更新过程中的数据,当前事务中 select 结果中没有。
也就是说,事务隔离级别并没有生效。
②分析过程
排查思路:使用 JdbcTemplate 以及原生 Jdbc API 开启事务隔离级别,把问题范围缩小并定位到数据库连接池组件(DBCP)上。
/** * 验证数据库连接的有效性 * @param sql 如果sql参数是null或为空字符串,代码会调用连接的isValid(timeout)方法来检查连接是否有效。 * 如果sql参数不为null,代码会执行这条SQL作为一个查询,并检查结果集(ResultSet)是否至少包含一行。 * @see org.apache.commons.dbcp2.PoolableConnectionFactory#validateConnection * @see org.apache.commons.dbcp2.PoolableConnection#validate */ public void validate(final String sql, int timeout) throws SQLException { if (sql == null || sql.length() == 0) { // java.sql.Connection.isValid if (!isValid(timeout)) { throw new SQLException("isValid() returned false"); } return; } if (!sql.equals(lastValidationSql)) { lastValidationSql = sql; // 此处创建了prepareStatement, 并缓存到当前 connection ❌ validationPreparedStatement = getInnermostDelegateInternal().prepareStatement(sql); } }👉DBCP validationQuery 事务隔离级别失效 Example. TransactionIsolationExample
Spring 事务开启前、数据库连接池获取 Connection 之前,由于DBCP 已经创建了 prepareStatement, 导致后续再次设置事务隔离级别失效。
-
-
JQuery-data-设计分析
JQuery 的data 功能可以动态的存取数据,不用频繁的操作DOM。
在事件处理程序之间传递数据非常有用。
JQuery Data
JQuery 定义一个
Data构造函数。默认实例化两个Data对象(dataUser、dataPriv)供功能使用。🎈数据的存取实现,就是通过 Data 来定义和实现。
①get 方法
function Data() { // 每次实例化 Data 对象时,都会生成一个唯一的 expando 属性值。 this.expando = jQuery.expando + Data.uid++; } // 通过设置原型对象,定义 Data 实例共享的方法和属性。 Data.prototype = { /** * 数据获取 * @param {*} owner 对应到 data功能,就是 Dom 对象 * @param {*} key 可以为空, 如果不指定,获取 owner 绑定的所有数据。 * @returns */ get: function( owner, key ) { return key === undefined ? // 类似于 owner[ this.expando ] this.cache( owner ) : // 如果存在 expando 属性值,则返回 owner[ this.expando ][ camelCaseKey ] 的值 owner[ this.expando ] && owner[ this.expando ][ jQuery.camelCase( key ) ]; } }② data 方法
抽象定义和初始化 Data 对象后,使用dataUser 操作Dom 存取数据变的很方便。
同时兼容了HTML5 data-* 特性,读取数据后类型转换并同步到 dataUser 中。
/** * 扩展 jQuery 实例方法,扩展后的方法可以在所有 jQuery 对象实例上调用。例如:$('p').data('someData'); * 对比:jQuery.extend。用于扩展 jQuery 构造函数的静态方法或属性。$.data(elem, 'someData') */ jQuery.fn.extend( { /** * 从dom 对象存取数据。value 有值是set 操作,无值是get 操作 * @param {*} key 数据key * @param {*} value 允许为空 * @returns */ data: function( key, value ) { var elem = this[ 0 ]; return access( this, function( value ) { var data; // get 操作 if ( elem && value === undefined ) { data = dataUser.get( elem, key ); if ( data !== undefined ) { return data; } // 兼容 HTML5 custom data-* attrs // 如果获取到 data-* 字符串,会尝试进行类型转换,或者json 反序列化 data = dataAttr( elem, key ); if ( data !== undefined ) { return data; } // We tried really hard, but the data doesn't exist. return; } // set 操作 this.each( function() { dataUser.set( this, key, value ); } ); }, null, value, arguments.length > 1, null, true ); } })③ 字符串类型转换
类型转换方便了取值后的操作,同时 JavaScript 类型的隐含转换也需要注意。🎈
// 用于匹配一个完整的 JSON 对象或数组。 // 1. 以 `{` 开头,以 `}` 结尾,中间可以包含任意字符。 // 2. 以 `[` 开头,以 `]` 结尾,中间可以包含任意字符。 var rbrace = /^(?:\{[\w\W]*\}|\[[\w\W]*\])$/; /** * 尝试对字符串类型转换 * @param {*} data HTML5 data-* attribute * @returns */ function getData(data) { if (data === "true") { return true; } if (data === "false") { return false; } if (data === "null") { return null; } // 检查 data 是否是一个数字的字符串的技巧 // 如果是数字,则返回true。 如果非数字, +data 结果为 NaN。 if (data === +data + "") { // 需要特别注意,+data 将空字符串 "" 转换为数字 0。 return +data; } if (rbrace.test(data)) { return JSON.parse(data); } return data; }JQuery expando 设计
JQuery.expando是 jQuery 用来在 DOM 元素或其他对象上存储数据的一个独特属性。简化示例
var elem = document.getElementById("example"); // jQuery 内部会做类似的操作 elem["jQuery123456789"] = { "myData": "someValue" }; // 获取数据 var data = elem["jQuery123456789"]["myData"]; console.log(data); // 输出 "someValue"设计分析
数据隔离/避免冲突
JQuery.expando是一个唯一的字符串(通常是由 jQuery 生成的一个带有前缀和随机数的字符串),确保它在所有元素和对象上都是唯一的。这可以避免与其他属性或数据键发生冲突。// Unique for each copy of jQuery on the page expando: "jQuery" + ( version + Math.random() ).replace( /\D/g, "" ),性能优化
直接在元素或对象上存储数据(而不是使用全局数据存储)可以提高性能。访问和修改元素上的属性通常比通过全局数据存储更快,因为它减少了查找和管理的开销。
-
Spring BeanCopier Bug
使用Spring BeanCopier 拷贝对象过程中,发现了一个Bug。
问题版本:3.2.0.RELEASE
Bug 场景
BeanCopier是一个非常高效的复制工具,因为它在运行时生成字节码来执行复制操作,而不是使用反射。①需要拷贝的类🧲
public static class TargetBean { private String name; // name's getters and setters // 没有 mixed 属性,Introspector 识别为布尔类型的 getter 方法 public String isMixed() { return name.contains("mix"); } }②拷贝异常❌
// 创建 BeanCopier 实例。 // 作用原理:使用CGlib库生成一个新类,该类的目的是实现Java Bean 之间属性的复制。 // 在匹配和获取 TargetBean setters过程中,出现异常 java.lang.NullPointerException BeanCopier copier = BeanCopier.create(TargetBean.class, TargetBean.class, false); // 复制属性 copier.copy(source, target, null);③日常日志
Exception in thread "main" java.lang.NullPointerException at org.springframework.cglib.core.ReflectUtils.getMethodInfo(ReflectUtils.java:424) at org.springframework.cglib.beans.BeanCopier$Generator.generateClass(BeanCopier.java:133) at org.springframework.cglib.core.DefaultGeneratorStrategy.generate(DefaultGeneratorStrategy.java:25) at org.springframework.cglib.core.AbstractClassGenerator.create(AbstractClassGenerator.java:216) at org.springframework.cglib.beans.BeanCopier$Generator.create(BeanCopier.java:90) at org.springframework.cglib.beans.BeanCopier.create(BeanCopier.java:50)问题分析
创建BeanCopier 实例的过程中,会根据TargetBean 遍历所有的 setter方法,尝试找到与之对应的 getter方法。
如上述的场景,针对属性“mixed”, 并没有对应的 setter方法,所以报错。
为什么 BeanCopier 会出现没有判断 null 的低级错误呢?🙉
①Introspector
Java Bean 是一种特殊的 Java 类,遵循特定的命名规则,比如属性的命名方式、事件处理方法等。
Introspector类使得开发者能够通过反射机制来分析一个 Java Bean 的属性和方法,而不需要直接与类的代码交互。// Introspector 识别的命名约定🧲 // 属性的读取方法(getter) static final String GET_PREFIX = "get"; // 属性的设置方法(setter) static final String SET_PREFIX = "set"; // 布尔属性的特殊读取方法。对于返回类型为 boolean 的属性,按照习惯,其读取方法可以使用 "is" 前缀而不是 "get"。 static final String IS_PREFIX = "is";根据约定,TargetBean 中的 isMixed 方法会识别为“mixed”属性的读取方法。
②BeanCopier
/** * 用CGlib库生成一个新类的过程,实现两个Java Bean之间属性的复制。 * @see org.springframework.cglib.beans.BeanCopier.Generator#generateClass */ public void generateClass(ClassVisitor v) { Type sourceType = Type.getType(this.source); Type targetType = Type.getType(this.target); PropertyDescriptor[] getters = ReflectUtils.getBeanGetters(this.source); // Bug: mixed 属性描述符也会返回到 setters集合中。实际上,该属性描述符并没有 WriteMethod。 // fix: setters = ReflectUtils.getBeanSetters(this.target); PropertyDescriptor[] setters = ReflectUtils.getBeanGetters(this.target); // 遍历所有的setter方法,尝试找到与之对应的getter方法。 for(int i = 0; i < setters.length; ++i) { PropertyDescriptor setter = setters[i]; PropertyDescriptor getter = (PropertyDescriptor)names.get(setter.getName()); if (getter != null) { MethodInfo read = ReflectUtils.getMethodInfo(getter.getReadMethod()); // mixed 属性的描述符(setter)对应的 WriteMethod = null, 所以抛异常。 MethodInfo write = ReflectUtils.getMethodInfo(setter.getWriteMethod()); if (compatible(getter, setter)) { e.dup2(); e.invoke(read); e.invoke(write); } } } }③导出动态类
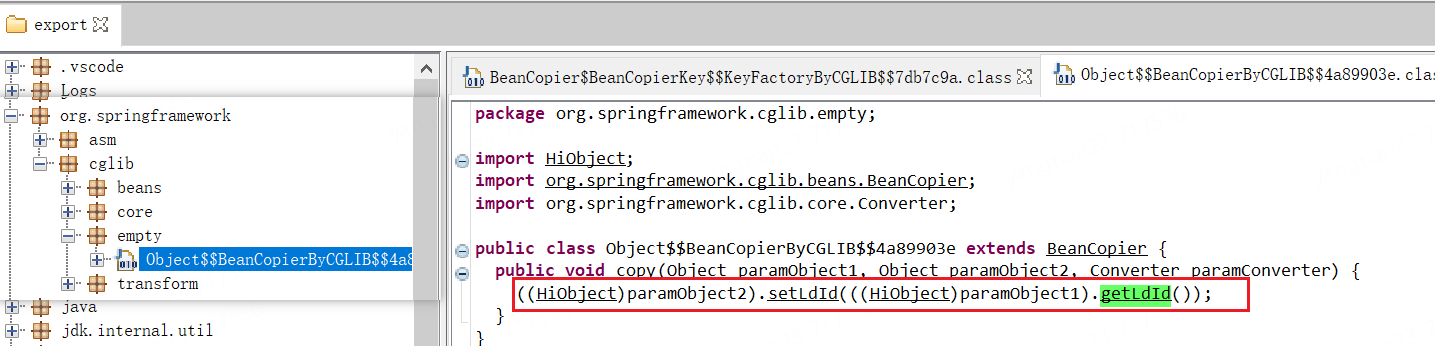
可以自定义 ClassFileTransformer, 拦截类的加载过程,并在类被加载到 JVM 之前导出类的字节码。
👉生成的动态类路径和 copy 接口实现
More
其实这个是CGLIB 的bug,从 Spring 3.2 开始,
CGLIB的功能被整合进了 Spring。这个Bug 在Spring 后续版本中已经被修复。✔
不过 cglib-nodep 修复比较慢, 使用cglib-nodep 需要注意这个问题。🎈
-
JDBC queryTimeout 实现机制
超时机制是个常见的设计,对于系统的稳定性和可靠性有重要的作用。
本文分别从 H2 和 Mysql 两种数据库的实现方式,来了解数据库查询的超时设计。