Welcome to MrRobot5's Blog!
记录源码阅读心得、工作遇到的问题-
Insight h2database SQL like 查询
我们认为的 SQL like 查询和优化技巧,设计的初衷和真正的实现原理是什么。
在 h2database SQL like 查询实现类中(CompareLike),可以看到 SQL 语言到具体执行的实现、也可以看到数据库尝试优化语句的过程,以及查询优化的原理。可以做为条件语句的经典案例去分析。
我们熟知的索引前缀匹配,实现过程和局限可以通过源码体现。
文章中的查询不只局限在 Select 语句,包括 Update、Delete。
SQL like 语句实现
根据之前的文章《Insight H2 database 数据查询核心原理》。 condition 执行的结果返回布尔类型,true or false。
任何表达式都可以是 condition, 根据转换规则,都可以转为布尔类型。
核心方法: org.h2.expression.CompareLike#getValue
/** * 执行 SQL like 表达式,返回 true or false. * 假设 SQL like 语句为 NAME like 'bj%' * @see org.h2.expression.CompareLike#getValue */ public Value getValue(Session session) { // 从当前行(session)获取对应列(left)的值。 left 对应为:NAME (ExpressionColumn) Value l = left.getValue(session); if (!isInit) { // 获取 like 表达式,正常情况下。 right 对应为:bj% (ValueExpression) Value r = right.getValue(session); String p = r.getString(); // 解析 like 表达式,方便后续识别和比对。主要是识别和定位通配符。 initPattern(p, getEscapeChar(e)); } String value = l.getString(); boolean result; if (regexp) { // 正则模式匹配 result = patternRegexp.matcher(value).find(); } else { // SQL Like 模式匹配。 字符循环比对。 result = compareAt(value, 0, 0, value.length(), patternChars, patternTypes); } return ValueBoolean.get(result); }SQL like 查询优化
like 查询比较损耗性能,针对特定的情况下,会进行查询优化。
prepare 阶段,重写查询语句,会彻底替换 Condition 对象。
之后,尝试增加索引查询条件,缩小数据遍历的范围。
①查询语句重写
核心方法: org.h2.expression.CompareLike#optimize
在查询准备阶段(org.h2.command.dml.Select#prepare),如果检测到如下的情况,会进行查询语句重写。
graph TD A[SQL: NAME LIKE 'bj%i'] --> B{prepare 阶段优化} B -->|模式为 '%'| C[重写为 IS NOT NULL] B -->|无通配符| D[重写为 EQUAL 等值匹配] B -->|前缀匹配 'bj%'| E[createIndexConditions] E --> F[提取前缀字符串 'bj'] F --> G[增加索引条件 NAME >= 'bj'] F --> H[计算终止字符 'bk'] H --> I[增加索引条件 NAME < 'bk'] I --> J[范围查询<br/>替代全表扫描] C --> K[执行优化后的条件] D --> K J --> K style E fill:#e1f5fe,stroke:#01579b style J fill:#e8f5e9,stroke:#2e7d32if ("%".equals(p)) { // optimization for X LIKE '%': convert to X IS NOT NULL return new Comparison(session, Comparison.IS_NOT_NULL, left, null).optimize(session); } if (isFullMatch()) { // 没有通配符的情况下,约等于等值匹配 // optimization for X LIKE 'Hello': convert to X = 'Hello' Value value = ValueString.get(patternString); Expression expr = ValueExpression.get(value); return new Comparison(session, Comparison.EQUAL, left, expr).optimize(session); }②增加索引查询条件
尝试限定查找范围 (start or end),而非全表扫描。
比如:select * from city where name like ‘朝阳%’;
等同于:select * from city where name >= ‘朝阳’ and name < ‘朝阴’;
核心方法:org.h2.expression.CompareLike#createIndexConditions
在查询准备阶段(org.h2.command.dml.Select#prepare),如果支持索引前缀匹配,那么就尝试计算匹配范围,增加索引查询条件,达到减少遍历的目的。
/** * like 前缀查询的本质是什么? * 拆解匹配查询字符串,把 like 查询,转为对应规律的字符串范围查询。 * 例如:NAME like 'bj%i' --> NAME >= 'bj' && NAME < 'bk' */ public void createIndexConditions(Session session, TableFilter filter) { // 使用正则模式查询,索引不生效。 NAME REGEXP '^bj.*' if (regexp) { return; } // 非当前表的关联查询语句,索引不生效 ExpressionColumn l = (ExpressionColumn) left; if (filter != l.getTableFilter()) { return; } String p = right.getValue(session).getString(); initPattern(p, getEscapeChar(e)); // 非前缀匹配,索引不生效 // private static final int MATCH(char) = 0, ONE(_) = 1, ANY(*) = 2; if (patternLength <= 0 || patternTypes[0] != MATCH) { // can't use an index return; } int dataType = l.getColumn().getType(); if (dataType != Value.STRING && dataType != Value.STRING_IGNORECASE && dataType != Value.STRING_FIXED) { // column is not a varchar - can't use the index return; } // 假设查询语句为: NAME like 'bj%i' // 从 patternChars(bj%i) 中提取最佳匹配的前缀字符串 bj。 String end; if (begin.length() > 0) { // 增加索引查询查询条件 NAME >= 'bj'。以此作为 like 前缀匹配的起始 filter.addIndexCondition(IndexCondition.get(Comparison.BIGGER_EQUAL, l, ValueExpression.get(ValueString.get(begin)))); char next = begin.charAt(begin.length() - 1); // search the 'next' unicode character (or at least a character that is higher) // 根据字符串顺序,尝试找到大于前缀的字符串。以此作为 like 前缀匹配的终止 for (int i = 1; i < 2000; i++) { end = begin.substring(0, begin.length() - 1) + (char) (next + i); if (compareMode.compareString(begin, end, ignoreCase) == -1) { // 增加索引查询查询条件 NAME < 'bk'。 j 的下一个字符即 k。 filter.addIndexCondition(IndexCondition.get(Comparison.SMALLER, l, ValueExpression.get(ValueString.get(end)))); break; } } } }其他
上述描述的过程,其中有一些细节,需要单独说明。
①通配符模式前缀查找
int maxMatch = 0; // 存储通配符模式前缀字符串, that is "begin" StringBuilder buff = new StringBuilder(); // 找到非通配符的前缀字符串。遍历 patternChars , 遇到非精确字符串, 终止。 while (maxMatch < patternLength && patternTypes[maxMatch] == MATCH) { buff.append(patternChars[maxMatch++]); }②索引条件校验
createIndexConditions 方式是把所有可以转为范围查找的列都加入了索引条件中(org.h2.table.TableFilter#indexConditions)。
有些列可能并没有索引,所以,需要在准备阶段(org.h2.table.TableFilter#prepare),剔除无效的索引条件。
/** * Prepare reading rows. This method will remove all index conditions that * can not be used, and optimize the conditions. * @see org.h2.table.TableFilter#prepare */ public void prepare() { // forget all unused index conditions // the indexConditions list may be modified here for (int i = 0; i < indexConditions.size(); i++) { IndexCondition condition = indexConditions.get(i); if (!condition.isAlwaysFalse()) { Column col = condition.getColumn(); if (col.getColumnId() >= 0) { if (index.getColumnIndex(col) < 0) { indexConditions.remove(i); i--; } } } } }Code Insight 环境
java -jar h2-1.4.184.jar org.h2.tools.Shell -url "jdbc:h2:~/test;MV_STORE=false" -user sa -password ""select * from city where name like 'bj%i'; SELECT * FROM INFORMATION_SCHEMA.INDEXES WHERE TABLE_NAME = 'CITY';总结
-
SQL like 模式匹配支持正则表达式和通配符两种。
-
常用的通配符模式采用约定的字符串匹配规则确定每一行数据是否符合要求。
-
正则模式匹配不支持优化,需要遍历目标表的每一行,性能损耗大。
-
使用前缀匹配的通配符模式匹配,尝试增加索引列的区间范围条件,优化扫描区间。
-
熟悉条件筛选的底层原理,趋利避害,达到数据查询的最佳性能。
-
-
Insight h2database 执行计划评估以及 Selectivity
生成执行计划是任何一个数据库不可缺少的过程。通过本文看执行计划生成原理。
最优的执行计划就是寻找最小计算成本的过程。
本文侧重 BTree 索引的成本计算的实现 以及 基础概念选择度的分析。
寻找最优执行计划
找到最佳的索引,实现最少的遍历,得到想要的结果
单表查询情况
/** * 根据查询条件,获取最佳执行计划. * * @param masks per-column comparison bit masks, null means 'always false', * see constants in IndexCondition * @return the plan item * @see org.h2.table.Table#getBestPlanItem */ public PlanItem getBestPlanItem(Session session, int[] masks, TableFilter filter, SortOrder sortOrder) { // 以扫描索引作为执行计划的默认索引 PlanItem item = new PlanItem(); item.setIndex(getScanIndex(session)); // 表的近似行数 * 10 作为默认成本,最差情况的 Cost 。 // long cost = 10 * (tableData.getRowCountApproximation() + Constants.COST_ROW_OFFSET); item.cost = item.getIndex().getCost(session, null, null, null); // 获取 table 包含的所有索引 ArrayList<Index> indexes = getIndexes(); if (indexes != null && masks != null) { // 跳过扫描索引(上述的 ScanIndex ) for (int i = 1, size = indexes.size(); i < size; i++) { Index index = indexes.get(i); // 计算当前索引的成本, 不同的索引有不同的成本计算公式。 double cost = index.getCost(session, masks, filter, sortOrder); // 记录/更新最小成本的索引,以此作为最佳执行计划 if (cost < item.cost) { item.cost = cost; item.setIndex(index); } } } return item; }多表查询情况
/** * 使用穷举策略寻找最佳执行计划 * 前提:少于 7 个表关联的情况下。 关联表太多的情况下,会采用随机 + 贪心算法,得出次优的执行计划 * @see org.h2.command.dml.Optimizer#calculateBestPlan */ private void calculateBruteForceAll() { TableFilter[] list = new TableFilter[filters.length]; // 关联表(filters) 排列组合 穷举策略,试算各种组合执行计划的成本 Permutations<TableFilter> p = Permutations.create(filters, list); // 如果组合遍历次数超过 127 次((x & 127) == 0),或者寻找的耗时超过 cost 的10倍,证明优化过程本末倒置,则停止这个过程。 for (int x = 0; !canStop(x) && p.next(); x++) { testPlan(list); } }BTree 索引的成本计算
/** * 计算 B-tree 索引中搜索数据所需的预估成本。 * Calculate the cost for the given mask as if this index was a typical * b-tree range index. This is the estimated cost required to search one * row, and then iterate over the given number of rows. * * @param masks the search mask. condition.getMask(indexConditions), 根据查询条件确定是哪种比较(EQUALITY、RANGE、START、END) * @param rowCount the number of rows in the index, 数据总行数 * @see org.h2.index.BaseIndex#getCostRangeIndex */ protected long getCostRangeIndex(int[] masks, long rowCount, TableFilter filter, SortOrder sortOrder) { rowCount += Constants.COST_ROW_OFFSET; long cost = rowCount; long rows = rowCount; // 总选择度,针对联合索引的情况,计算各个 column 综合参数 int totalSelectivity = 0; // 没有查询条件的情况,预估成本是 rowCount, 等于全表扫描 if (masks == null) { return cost; } // 遍历索引的 columns, 做两件事:查询条件是否匹配索引列,匹配的成本计算 for (int i = 0, len = columns.length; i < len; i++) { Column column = columns[i]; int index = column.getColumnId(); int mask = masks[index]; if ((mask & IndexCondition.EQUALITY) == IndexCondition.EQUALITY) { // 等值比较情况下,如果是 unique 索引,cost 相比以下是最小的。 if (i == columns.length - 1 && getIndexType().isUnique()) { cost = 3; break; } // 动态计算总选择度,查询条件与索引 column 重合度越高,选择越大 // 为了便于理解,公式还可以改写为:totalSelectivity = totalSelectivity + (100 - totalSelectivity) * column.getSelectivity() / 100; // 也就是:总选择度 = 已有的选择度 + 已有的非选择度中再次用 column 选择度计算的增量 totalSelectivity = 100 - ((100 - totalSelectivity) * (100 - column.getSelectivity()) / 100); // 估算当前选择度下的非重复的数据行数(假设索引的选择性是均匀分布的) long distinctRows = rowCount * totalSelectivity / 100; if (distinctRows <= 0) { distinctRows = 1; } // 选择度越大,这里的 rows,也就是 cost 越小。 rows = Math.max(rowCount / distinctRows, 1); // cost >= 3 cost = 2 + rows; } else if ((mask & IndexCondition.RANGE) == IndexCondition.RANGE) { cost = 2 + rows / 4; break; } else if ((mask & IndexCondition.START) == IndexCondition.START) { cost = 2 + rows / 3; break; } else if ((mask & IndexCondition.END) == IndexCondition.END) { cost = rows / 3; break; } else { // 如果索引的 columns 不支持匹配,则直接终止计算。对于联合索引的情况,如果首列不支持匹配,那么认定此索引失效。 break; } } // 当查询中的 ORDER BY 与索引的排序顺序匹配时, // 使用这个索引进行查询通常比使用其他索引更加高效,因此查询优化器会相应地调整这个索引的成本。 if (sortOrder != null) { boolean sortOrderMatches = true; int coveringCount = 0; int[] sortTypes = sortOrder.getSortTypes(); for (int i = 0, len = sortTypes.length; i < len; i++) { // 匹配计算... coveringCount++; } if (sortOrderMatches) { // 当有两个或更多的覆盖索引可供选择时,查询优化器会倾向于选择覆盖更多列的索引。 // 覆盖更多列的索引 cost 更少来体现。 cost -= coveringCount; } } return cost; }Selectivity
概念
Selectivity is used by the cost based optimizer to calculate the estimated cost of an index.
Selectivity 100 means values are unique, 10 means every distinct value appears 10 times on average.
人工指定 Selectivity
-- sets the selectivity (1-100) for a column. ALTER TABLE TEST ALTER COLUMN NAME SELECTIVITY 100;人工更新 Selectivity
-- Updates the selectivity statistics of tables. ANALYZE SAMPLE_SIZE 1000;自动更新 Selectivity
随着表数据的更新操作,对应列的 Selectivity 也在发生变化。基于累计值 analyzeAuto 来决定什么时候触发Analysis, 也就是更新 Selectivity。
/** * 默认为 2000 ,也就是说,对表进行大约 2000 次更改后,将对每个用户表运行 ANALYZE。 * 自数据库启动以来,每次运行 ANALYZE 的时间间隔都会加倍。 * 它不会在本地临时表上运行,也不会在 SELECT 触发器的表上运行。 * @see org.h2.engine.DbSettings#analyzeAuto */ public final int analyzeAuto = get("ANALYZE_AUTO", 2000);
-
Insight H2 database 数据查询核心原理
本文目标是:了解查询的核心原理,对比 SQL 查询优化技巧在 h2database 中的落地实现。
前提:为了贴近实际实际,本文 Code Insight 基于 BTree 存储引擎。
数据查询核心原理
数据库实现查询的原理:遍历表/索引,判断是否满足
where筛选条件,添加到结果集。简单通用。对于选择表还是索引、如何遍历关联表、优先遍历哪个表、怎样提升遍历的效率,这个就是数据库查询复杂的地方。
/** * 查询命令实现查询的主要过程 * @see org.h2.command.dml.Select#queryFlat */ private void queryFlat(int columnCount, ResultTarget result, long limitRows) { // 遍历单表 or 关联表。topTableFilter 可以简单理解为游标 cursor。 while (topTableFilter.next()) { // 判断是否符合 where 筛选条件 if (condition == null || Boolean.TRUE.equals(condition.getBooleanValue(session))) { Value[] row = new Value[columnCount]; // 填充select 需要的 columns ① for (int i = 0; i < columnCount; i++) { Expression expr = expressions.get(i); row[i] = expr.getValue(session); } // 保存符合条件的数据,这个对应 resultSet result.addRow(row); // 没有 sort 语句的情况下,达到 limitRows, 终止 table scan ② if ((sort == null || sortUsingIndex) && limitRows > 0 && result.getRowCount() >= limitRows) { break; } } } }Join 查询核心原理
基于状态机模式,实现多表嵌套循环遍历。
使用的 Join 算法是: Nested Loop Join。
状态变迁:BEFORE_FIRST –> FOUND –> AFTER_LAST
/** * Check if there are more rows to read. * 遍历的数据 row 记录在当前 session 中,随时随地可以获取 * * @return true if there are * @see org.h2.table.TableFilter#next */ public boolean next() { // 遍历结束,没有符合的条件的 row if (state == AFTER_LAST) { return false; } else if (state == BEFORE_FIRST) { // cursor 遍历初始化, 如果基于索引的游标,则可以提前锁定数据范围。③ cursor.find(session, indexConditions); if (!cursor.isAlwaysFalse()) { // 如果包含 join 表,重置关联表的状态机。 if (join != null) { join.reset(); } } } else { // state == FOUND || NULL_ROW 的情况 // 嵌套遍历 join 关联表。这是个递归调用关联表的过程。 if (join != null && join.next()) { return true; } } // 表/索引数据扫描,匹配filterCondition,直到找到符合的 row while (true) { if (cursor.isAlwaysFalse()) { state = AFTER_LAST; } else { if (cursor.next()) { currentSearchRow = cursor.getSearchRow(); current = null; state = FOUND; } else { state = AFTER_LAST; } } // where 条件判断 if (!isOk(filterCondition)) { continue; } // 嵌套遍历 join 关联表。主表的每一行 row,需要遍历关联子表一次。④ if (join != null) { join.reset(); if (!join.next()) { continue; } } // check if it's ok if (state == NULL_ROW || joinConditionOk) { return true; } } state = AFTER_LAST; return false; }获取查询数据
从遍历的 row 中,获取 select 语句需要的 column 数据。
对应的 Cursor 实现是:org.h2.index.PageBtreeCursor
/** * 根据 columnId 获取对应的值 * @see org.h2.table.TableFilter#getValue */ public Value getValue(Column column) { if (current == null) { // 优先从当前遍历的 row 获取数据。 // 如果是索引中的 row,不会包含所有的行,会有取不到的情况 Value v = currentSearchRow.getValue(columnId); if (v != null) { return v; } // 如果没有,再尝试从原始表 row 存储中获取数据。⑤ // 对应的实现: currentRow = index.getRow(session, currentSearchRow.getKey()); current = cursor.get(); if (current == null) { return ValueNull.INSTANCE; } } return current.getValue(columnId); }常用的 SQL 查询优化技巧
分别对应上述源代码注释的数字角标。
①避免使用 SELECT *:只选择需要的列
如果使用 select *, 即使使用了索引查询。也需要取原数据行的所有数据(⑤)。会进行数据的二次读取,也就是回表查询。影响了性能。
②避免使用 ORDER BY, 尽量使用LIMIT
使用 LIMIT:如果只需要部分结果,可以使用 LIMIT 子句限制返回的行数,避免检索整个结果集。
如上源代码,如果没有 Order By,有limit 限制情况下,可以中途结束表遍历。
如果有 Order By 的情况下,肯定要执行完成整个扫描遍历的过程,最终在 result 结果集中再一次进行排序计算。
③使用索引:确保表中的列上有适当的索引,以加快查询速度。
如果使用索引,在初始化扫描阶段,会给 cursor 一定的范围,避免全表扫描。极大的缩小的查询范围。
④减少连接的表的数量:如果可能,尽量减少查询中的表的数量。
无需多言,嵌套递归查询,理论上是所有表的笛卡尔积。
⑤使用覆盖索引:一个查询的所有列都包含在索引中。
这样查询可以只扫描索引而不需要回表。例如,如果你的查询是 SELECT id, name FROM users WHERE age = 30,那么在 age, id, name 上创建一个复合索引可以避免回表。
其他
Nested Loop Join
// 用伪代码表示,可以更清晰理解上述 join 遍历的过程 for (r in R) { for (s in S) { if (r satisfy condition s) { output <r, s>; } } }MySQL 中的Nested Loop Join
MySQL官方文档中提到,MySQL只支持Nested Loop Join这一种join algorithm.
MySQL resolves all joins using a nested-loop join method.
This means that MySQL reads a row from the first table, and then finds a matching row in the second table, the third table, and so on.
-
SpringMVC 文件上传相关源码梳理
记录 SpringMVC 文件上传相关源码梳理
示例代码
@Controller public class FileUploadController { @PostMapping("/form") public String handleFormUpload(@RequestParam("name") String name, @RequestParam("file") MultipartFile file) { if (!file.isEmpty()) { byte[] bytes = file.getBytes(); // store the bytes somewhere return "redirect:uploadSuccess"; } return "redirect:uploadFailure"; } }Commons FileUpload
Form-based File Upload in HTML 定义,Commons FileUpload 是该定义的实现。
tomcat-embed-core
SpringBoot 项目中引用了
tomcat-embed-core,这个包内部打包了 Commons FileUpload。从 web 容器层提供了文件上传的支持。/** * 调用 Commons FileUpload, 实现 http 提交文件的解析 * 对应上述using 教程的 The simplest case * @see org.apache.catalina.connector.Request#parseParts */ private void parseParts(boolean explicit) { // Create a new file upload handler DiskFileItemFactory factory = new DiskFileItemFactory(); try { factory.setRepository(location.getCanonicalFile()); } catch (IOException ioe) { parameters.setParseFailedReason(FailReason.IO_ERROR); partsParseException = ioe; return; } factory.setSizeThreshold(mce.getFileSizeThreshold()); ServletFileUpload upload = new ServletFileUpload(); upload.setFileItemFactory(factory); upload.setFileSizeMax(mce.getMaxFileSize()); upload.setSizeMax(mce.getMaxRequestSize()); }SpringMVC 处理流程
StandardServletMultipartResolver
Auto-configuration for multi-part uploads.
protected void doDispatch(HttpServletRequest request, HttpServletResponse response) throws Exception { boolean multipartRequestParsed = false; try { ModelAndView mv = null; Exception dispatchException = null; try { // 判断当前的请求是否为文件上传。如果是,当前的request 转为 multipart request。 // 如果不是,返回入参的 request。 processedRequest = checkMultipart(request); multipartRequestParsed = (processedRequest != request); // 处理当前的请求... } } finally { // Clean up any resources used by a multipart request. if (multipartRequestParsed) { // 简单来讲,就是 request.getParts().delete(); cleanupMultipart(processedRequest); } } }SpringBoot 配置
spring: servlet: multipart: # max-file-size specifies the maximum size permitted for uploaded files. The default is 1MB max-file-size: 32MB max-request-size: 32MBMultipartAutoConfiguration
Auto-configuration for multi-part uploads.
@see org.springframework.boot.autoconfigure.web.servlet.MultipartAutoConfiguration
MultipartAutoConfiguration 负责注册 StandardServletMultipartResolver Bean。
DispatcherServlet 初始化过程中会尝试获取该 Bean。
/** * DispatcherServlet 初始化 multipartResolver。如果能获取到bean,支持文件上传解析,否则不支持。 * @see org.springframework.web.servlet.DispatcherServlet#initStrategies */ private void initMultipartResolver(ApplicationContext context) { try { this.multipartResolver = context.getBean(MULTIPART_RESOLVER_BEAN_NAME, MultipartResolver.class); } }/** * Max file size .* 如果不配置 max-file-size,默认为 1MB,来源于此 * @see org.springframework.boot.autoconfigure.web.servlet.MultipartProperties */ private DataSize maxFileSize = DataSize.ofMegabytes(1);StringToDataSizeConverter
配置文件解析,字符串“32MB” 转为 DataSize 对象。
org.springframework.boot.convert.StringToDataSizeConverter
/** * DataSize 格式定义。 * ^ $匹配字符串的开头和结尾,严格匹配整个字符串。 * ([+\\-]?\\d+) 匹配一个可选的正负号后跟着一或多个数字 * ([a-zA-Z]{0,2}) 匹配零到两个字母(大小写不限) */ Pattern.compile("^([+\\-]?\\d+)([a-zA-Z]{0,2})$");
-
Mybatis 分页插件 JDK 动态代理案例分析
背景
工程A 代码迁移到 工程B 过程中,涉及到分页插件的附带迁移和融合。
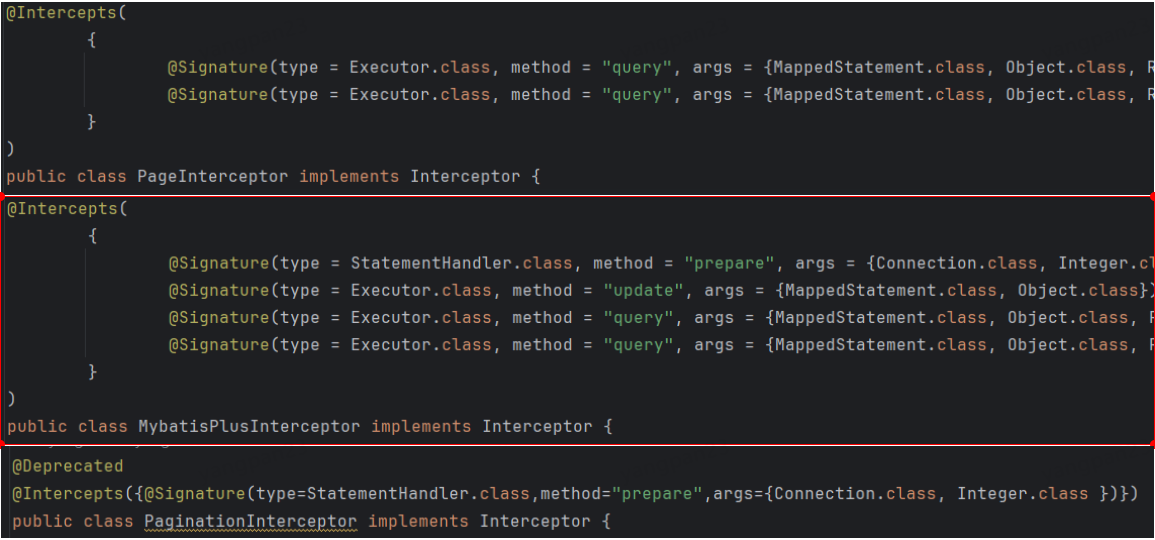
工程B 已有 com.github.pagehelper.PageInterceptor、 com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor 前提下。
引入了另外一个分页插件 com.foo.common.interceptor.PaginationInterceptor
运行时异常
调用 PaginationInterceptor 分页插件时,报错如下:
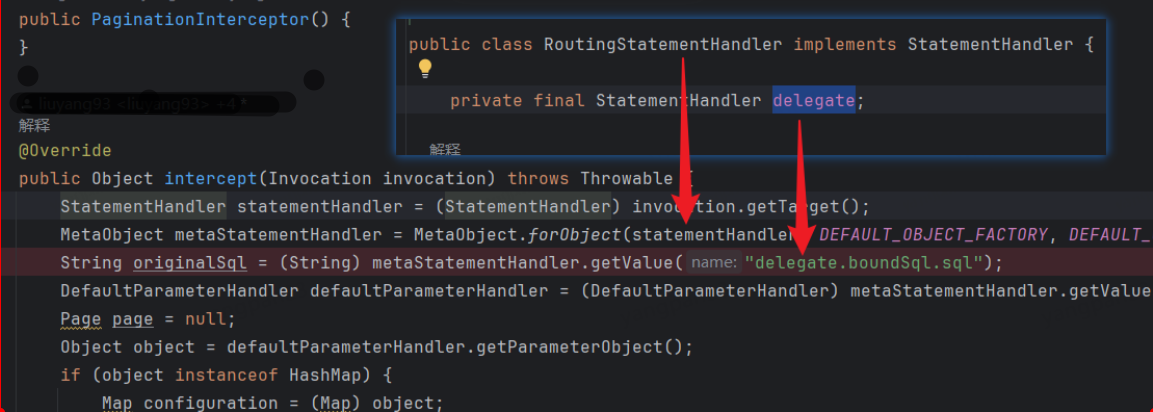
Caused by: org.apache.ibatis.reflection.ReflectionException: There is no getter for property named ‘delegate’ in ‘class com.sun.proxy.$Proxy280’
分页插件 PaginationInterceptor
Debug 运行环境差异
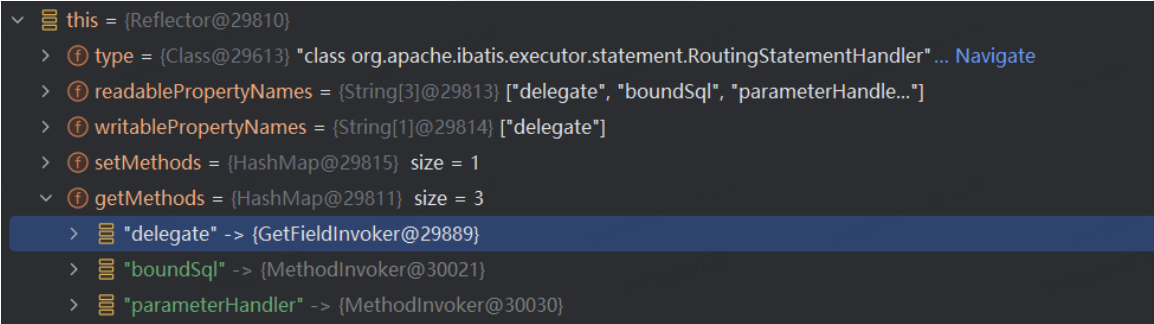
没有经过代理的对象-工程A 环境
经过代理的对象-工程B 环境
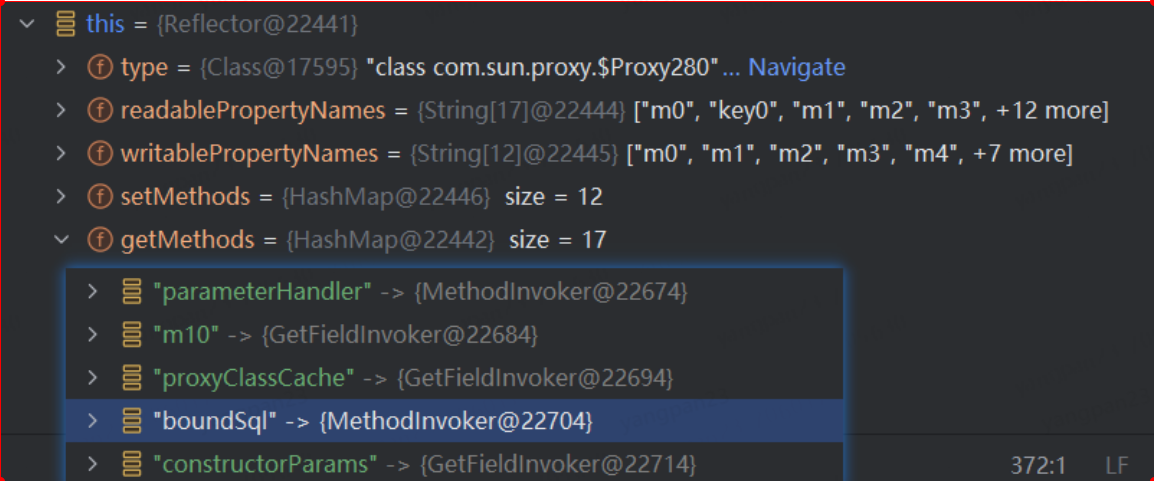
动态代理分析
分页插件 Pointcut